
What is Hadoop?
Hadoop Connector is an application connector provided by Boomi to connect to and exchange data from the various directories on the Hadoop Distributed File System (HDFS) server. Using this connector, you can directly connect with the Hadoop Distributed File System (HDFS) server and GET, CREATE, EXECUTE, and DELETE data stored in the directories of the HDFS server.
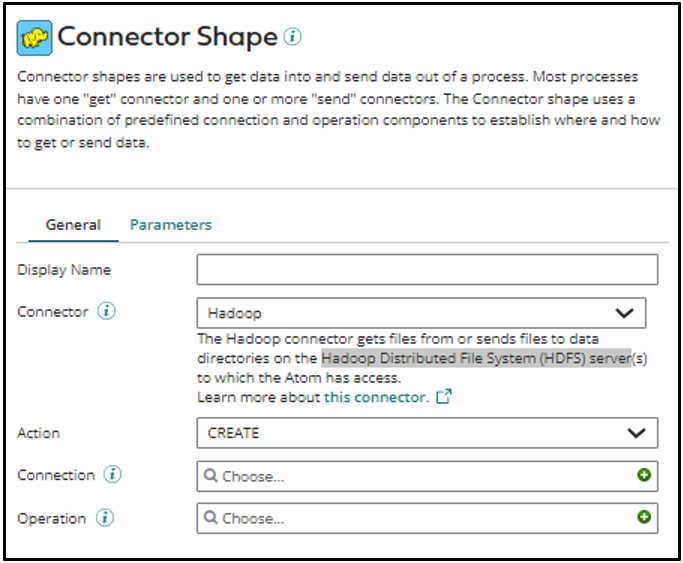
Like every other connector in Boomi, Hadoop Connector also requires the Hadoop Connection and Hadoop Operation components to connect to the Hadoop Distributed File System (HDFS) server.
Hadoop Connection:
Stores the essential details required for establishing the Boomi- HDFS server connectivity.
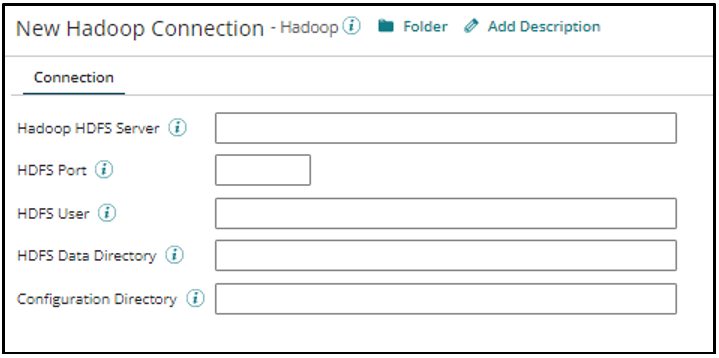
- Name: One can set the desired name for the connection in this field.
- Hadoop HDFS Server: This field is used to store the hostname or IP of the Hadoop server.
- HDFS Port: Stores the port number of the Hadoop Distributed File System (HDFS) server.
- HDFS User: Stores the Username having access to Hadoop Distributed File System (HDFS) server.
- HDFS Data Directory: Stores the Directory where the required data exists in Hadoop Distributed File System (HDFS) server.
- Configuration Directory: Specify a path on the local file system to a network location where additional customized configuration files to be used by the connector are located.
Hadoop Operation:
Defines the action that needs to be performed on a specific Hadoop object using the Hadoop Connection.
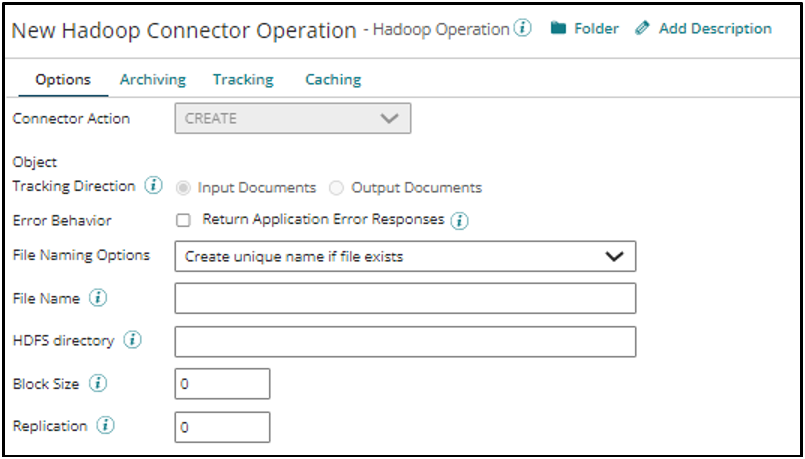
- Name: One can set the desired operation name in this field.
- Object: The Hadoop Object against which you want to perform the said action.
- Request Profile: Defines the schema/structure of the request sent to the Hadoop server.
- Response Profile: Defines the schema/structure of the response received by the Hadoop server.
- Tracking Direction: This enables you to choose whether to track the input or output document and display the same in process reporting.
- Error Behavior: Helps store the error response received from the Hadoop server.
- Return Application Error Response: If selected processing continues and passes the error response to the next component processed as the connection output, otherwise stops the processing and reports an error in process reporting.
- File Naming Options: Using this you can decide whether to create a new file, overwrite a file or abort the request if a file with the same name already exists.
- File name: Stores the file name that needs to be created on Hadoop Server.
- HDFS Directory: Stores the name of the directory where the file needs to be created on the Hadoop Server.
- Block Size: Stores the block size to be consumed on HDFS.
- Replication: Stores the replication factor for each block.
Cover Photo by Mika Baumeister on Unsplash

